
Depuis quelques mois, vous avez pu apercevoir dans les couloirs de Novawest Angèle Boué aux côtés de la Team Data. Angèle prépare un Master en Ingénierie Statistique pour devenir Data Analyst, en partenariat avec l’université de Nantes, et passe quelques mois chez RCA en stage.
On lui a confié un sujet d’étude : la réalisation d’un benchmarking sectoriel pour nos utilisateurs !
Nous allons essayer de vous expliquer simplement, son job, sa mission et l’application possible pour nos clients si ce projet aboutit à une nouvelle fonctionnalité.
A la conquête des données
“J’ai une formation qui me permet d’utiliser les algos, les exploiter et analyser des données.”
L’idée pour Angèle est de participer à la conception d’un nouveau produit pour nos clients et utilisateurs. Le concept : permettre aux entreprises utilisatrices de pouvoir se comparer entre elles en fonction de leur secteur d’activité. Par exemple, un boulanger, qui se rendrait compte que son coût d’achat des matières premières est bien plus élevé que son concurrent local et décide de changer de fournisseur.
Ou aller chercher la data ?
Depuis sa création, MEG enregistre un nombre de données phénoménal : date de création de l’entreprise, chiffre d’affaires, nombre de factures, de devis… Ce sont ces données extraites de MEG qui sont à la base du travail d’Angèle.
Son outil privilégié : Snowflake, pour créer et exploiter ces tables de données (TDD). Les TDD représentent des tableaux avec de nombreuses lignes et colonnes dans lesquelles sont consignées un gros volume de données utilisateurs. Un peu comme un tableau excel à plusieurs entrées, mais en plus gros. Au total, il existe 218 tables différentes dans MEG !
Comment la ranger ?
Il faut imaginer un arbre sur lequel plein de branches représentent une table de données et chaque feuille représente une donnée d’un utilisateur. Le tronc, lui, représente la grosse table qui fait le lien. Les branches peuvent donc communiquer entre elles en passant par le tronc. Sur chaque branche, au moins une donnée est commune aux autres : l’ID utilisateur MEG. Ainsi, cela permet de rapprocher certaines données pourtant pas issues des mêmes tables. Un peu comme une recherche V sur excel 😉
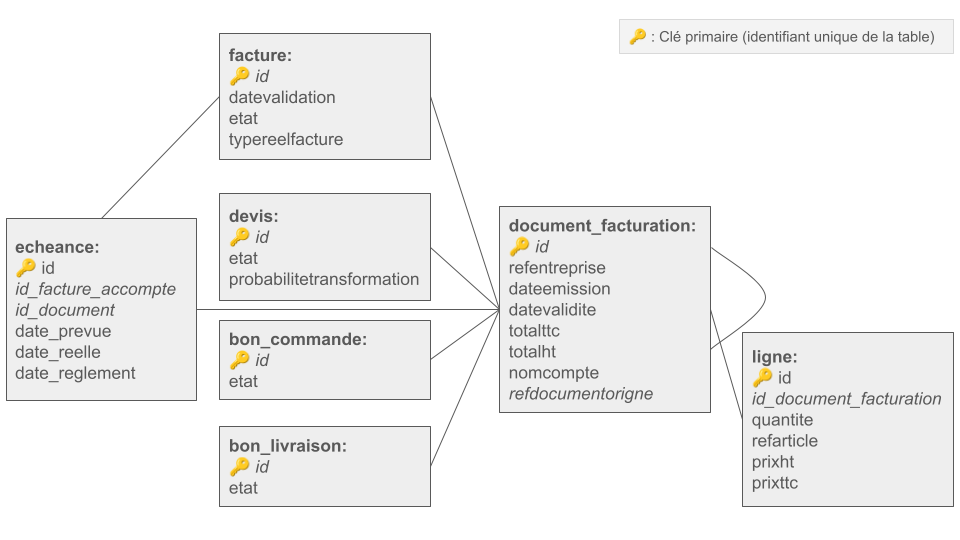
Schéma simplifié des tables et des différents liens possibles entre elles.
L’équipe Data est donc chargée de récupérer ces tables en fonction des demandes puis de les injecter dans Snowflake. Ensuite, Angèle utilise le langage de programmation “python” pour interagir avec ces données. Il s’agit du langage principalement utilisé dans la Data.
L’idée du stage est de créer une grosse table de données qui prend sa source dans les 218 existantes. Ces données seront ensuite exploitées pour proposer une solution de benchmarking sectoriel.
Comment qualifier la donnée ?
Être Data Analyst ce n’est pas être Expert-Comptable ! Pour chaque environnement métier, il est important de prendre du temps pour prendre connaissance de la donnée et naviguer dedans aisément. ”Je n’y connais rien en comptabilité, mais l’idée c’est de s’imprégner de l’expertise métier et de se rapprocher des experts”, confirme Angèle. Il faut alors faire preuve d’une grande capacité d’adaptation pour appréhender les enjeux métier.
L’un des premiers défis est d’identifier quelles données brutes existent chez RCA et lesquelles seront pertinentes pour l’outil de benchmarking sectoriel. Ainsi, Angèle a énormément découvert et appris sur l’univers de l’expertise comptable lors de cette première phase d’identification et de récupération de données.
De l’exploration à l’algorithme
La première étape pour Angèle est donc de créer une base de données suffisamment importante pour l’intégrer à un algorithme. Cette première étape est constituée de nombreuses informations :
- Des données qualitatives : adresse, nombre de salariés, SIRET, type de de TVA, date de création…
- Et des données quantitatives : chiffre d’affaires (avec un extract de facturation ou caisse), ratios de comparaison N, N-1, CA par mois, nombre de factures…
Pour les utilisateurs premium, on peut même extraire des données sur les matières premières, les charges, le nombre de factures, de clients, de devis et même le taux de transformation des devis en facture. Angèle va également aller chercher des tables de données auprès d’autres structures pour qualifier ces données, par exemple, un tableau de conversion de devises, récupéré auprès de la BPI.
C’est lors de la deuxième étape qu’entre en scène l’algorithme !
L’idée est de pouvoir en tester plusieurs (3 à 4), à choisir parmi des algos déjà existants. Il en existe plusieurs proposés en open source.
Elle va tester leur performance et leurs résultats puis les paramétrer pour arriver à un résultat le plus pertinent possible pour les utilisateurs de MEG.
Et il y a du travail car la fameuse table fait plus de 5 millions de lignes !
Angèle a donc pour but d’explorer l’or noir de RCA, comme est communément appelé la Data aujourd’hui. Elle va exploiter le potentiel de ces informations et les possibilités pour nos clients, qui pourront ainsi faire évoluer les produits proposés à nos utilisateurs.
Marie CAUCHY
Cheffe de Projet Marque Employeur & RSE


